Dictionaries and Frequency Tables
Kuis
1. Storing
Data
Instructions
Store the data in the table above
using two different lists.
Assign the list ['4+', '9+',
'12+', '17+'] to a variable named content_ratings.
Assign the list [4433, 987, 1155, 622] to a variable named numbers.
Store the data in the table above using a list of lists. Assign the list
[['4+', '9+', '12+', '17+'], [4433, 987, 1155, 622]] to a variable named
content_rating_numbers.

2. Dictionaries
Instructions
Map content ratings to their
corresponding numbers by recreating the dictionary above: {'4+': 4433, '9+':
987, '12+': 1155, '17+': 622}. Assign the dictionary to a variable named
content_ratings.
Print content_ratings and examine the output carefully. Has the order we used
to create the dictionary been preserved? In other words, is the output
identical to {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}? We'll discuss
more about this on the next screen.

3. Indexing
Instructions
Retrieve values from the
content_ratings dictionary.
Assign the value at index '9+' to
a variable named over_9.
Assign the value at index '17+' to a variable named over_17.
Print over_9 and over_17.

4. Alternative
Way of Creating a Dictionary
Instructions
Use the new technique we learned
to map content ratings to their corresponding numbers inside a dictionary.
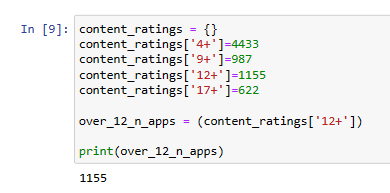
Create an empty dictionary named
content_ratings.
Add the index:value pairs one by one using the dictionary_name[index] = value
technique. This should be the final form of the dictionary: {'4+': 4433, '9+':
987, '12+': 1155, '17+': 622}.
Retrieve the value at index 12+ from the content_ratings dictionary. Assign it
to a variable named over_12_n_apps.
5. Key
Value Pair
Instructions
Create the following dictionary
and assign it to a variable named d_1:
{'key_1': 'first_value',
'key_2': 2,
'key_3': 3.14,
'key_4': True,
'key_5': [4,2,1],
'key_6': {'inner_key' : 6}
}
2.Examine the code below and determine whether it'll raise an error or not. If
you think it'll raise an error, then assign the boolean True to a variable
named error, otherwise assign False.
{4: 'four',
1.5: 'one point five',
'string_key': 'string_value',
True: 'True',
[1,2,3]: 'a list',
{10: 'ten'}: 'a dictionary'}

6. Checking
for Memberships
Instructions
Using the in operator, check
whether the following values exist as dictionary keys in the content_ratings
dictionary:
The string '9+'. Assign the
output of the expression to a variable named is_in_dictionary_1.
The integer 987. Assign the output of the expression to a variable named
is_in_dictionary_2.
Combine the output of an expression containing in with an if statement. If the
string '17+' exists as dictionary key in content_ratings, then:
Assign the string "It
exists" to a variable named result.
Print the result variable.

7. Counting
with Dictionaries
Instructions
Count the number of times each
unique content rating occurs in the data set.
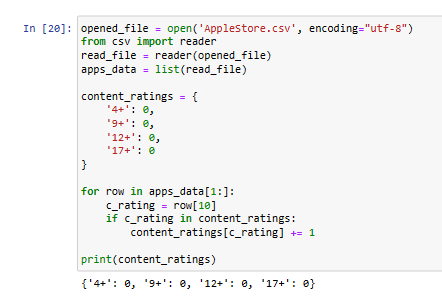
Create a dictionary named content_ratings where the keys are the unique content
ratings and the values are all 0 (the values of 0 are temporary at this point,
and they'll be updated).
Loop through the apps_data list of lists. Make sure you don't include the
header row. For each iteration of the loop:
Assign the content rating value to a variable named c_rating. The content
rating is at index number 10 in each row.
Check whether c_rating exists as a key in content_ratings. If it exists, then
increment the dictionary value at that key by 1 (the key is equivalent to the
value stored in c_rating).
Outside the loop, print content_ratings to check whether the counting worked as
expected.
8. Finding
the Unique Values
Instructions
Count the number of times each
unique content rating occurs in the data set while finding the unique values
automatically. Create an empty dictionary named content_ratings.
Loop through the apps_data list of lists (make sure you don't include the
header row). For each iteration of the loop:
Assign the content rating value to a variable named c_rating. The content
rating is at index number 10.
Check whether c_rating exists as a key in content_ratings.
If it exists, then increment the dictionary value at that key by 1 (the key is
equivalent to the value stored in c_rating).
Else, create a new key-value pair in the dictionary, where the dictionary key
is c_rating and the dictionary value is 1.
Outside the loop, print content_ratings to check whether the counting worked as
expected.

9. Proportions
and Percentage
Instructions
Count the number of times each
unique genre occurs.
Create an empty dictionary named genre_counting.
Loop through the apps_data list of lists (make sure you don't include the
header row). For each iteration of the loop:
Assign the genre to a variable named genre. The genre comes as a string and has
the index number 11.
Check whether genre exists as a key in genre_counting.
If it exists, then increment the dictionary value at that key by 1 (the key is
equivalent to the value stored in genre).
Else, create a new key-value pair in the dictionary, where the dictionary key
is genre and the dictionary value is 1.
Outside the loop, print genre_counting and try to determine what's the most
common app genre in our data set.

10. Looping
Over Dictionaries
Instructions
Loop over the content_ratings
dictionary and transform the frequencies to percentages. For every iteration of
the loop:
Transform the dictionary value
(the frequency) to a proportion by dividing it by the total number of apps.
Transform the updated dictionary value (the proportion) to a percentage by multiplying
it by 100.
Find out the percentage of apps that have a content rating of '17+'. Assign
your answer to a variable named percentage_17_plus.
Find out the percentage of apps
that can be downloaded by a 15-year-old. Assign your answer to a variable named
percentage_15_allowed.

11. Keeping
the Dictionaries Separate
Instructions
Transform the frequencies inside
content_ratings to proportions and percentages while creating separate
dictionaries for each.
Assign the dictionary storing
proportions to a variable named c_ratings_proportions.
Assign the dictionary storing percentages to a variable named
c_ratings_percentages.
Optional challenge: try to solve this exercise using a single for loop
(solution to this challenge provided).

12. Frequency
Tables for Numerical Columns
Instructions
Extract the values in the
size_bytes column in a separate list.
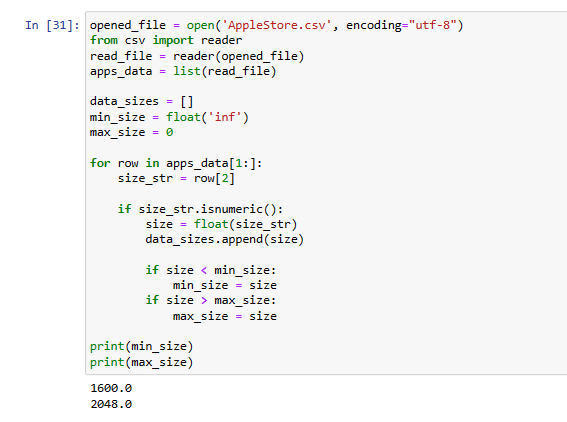
Create an empty list named
data_sizes.
Loop through apps_data (make sure you don't include the header row) and for
every iteration:
Store the data size as a float in a variable named size (the index number for
the data size is 2).
Append size to the data_sizes list.
Find out the minimum and the maximum app data size.
Assign the minimum value to a
variable named min_size.
Assign the maximum value to a variable named max_size.
13. Filtering
for the Intervals
Instructions
Begin by finding the minimum and
maximum value in the rating_count_tot column.
Extract the values in the
rating_count_tot column (index number 5) in a separate list (don't forget to
convert to integer or float).
Find out the minimum and maximum value of that list using the min () and the
max () commands.
Based on the minimum and maximum value you've found, choose a few intervals
(try to choose five intervals or less).
We've disabled answer checking
for this exercise to give you the freedom to choose the intervals you find
suitable (there's not a fixed solution for this exercise). You can see the
intervals we chose in the solution.
Once you've chosen the intervals, compute the frequency of apps for each
interval. Store the frequency table in a dictionary.
Create a dictionary with
intervals as dictionary keys and zeros as dictionary values.
Loop through the apps_data data set. Count the frequency of each interval using
an if statement followed by a series of elif clauses.
Inspect the frequency table and analyze the results.
.PNG)
.PNG)
.png)

Komentar
Posting Komentar